


New Study Challenges Long-Held Assumption About How AI “Sees” Images
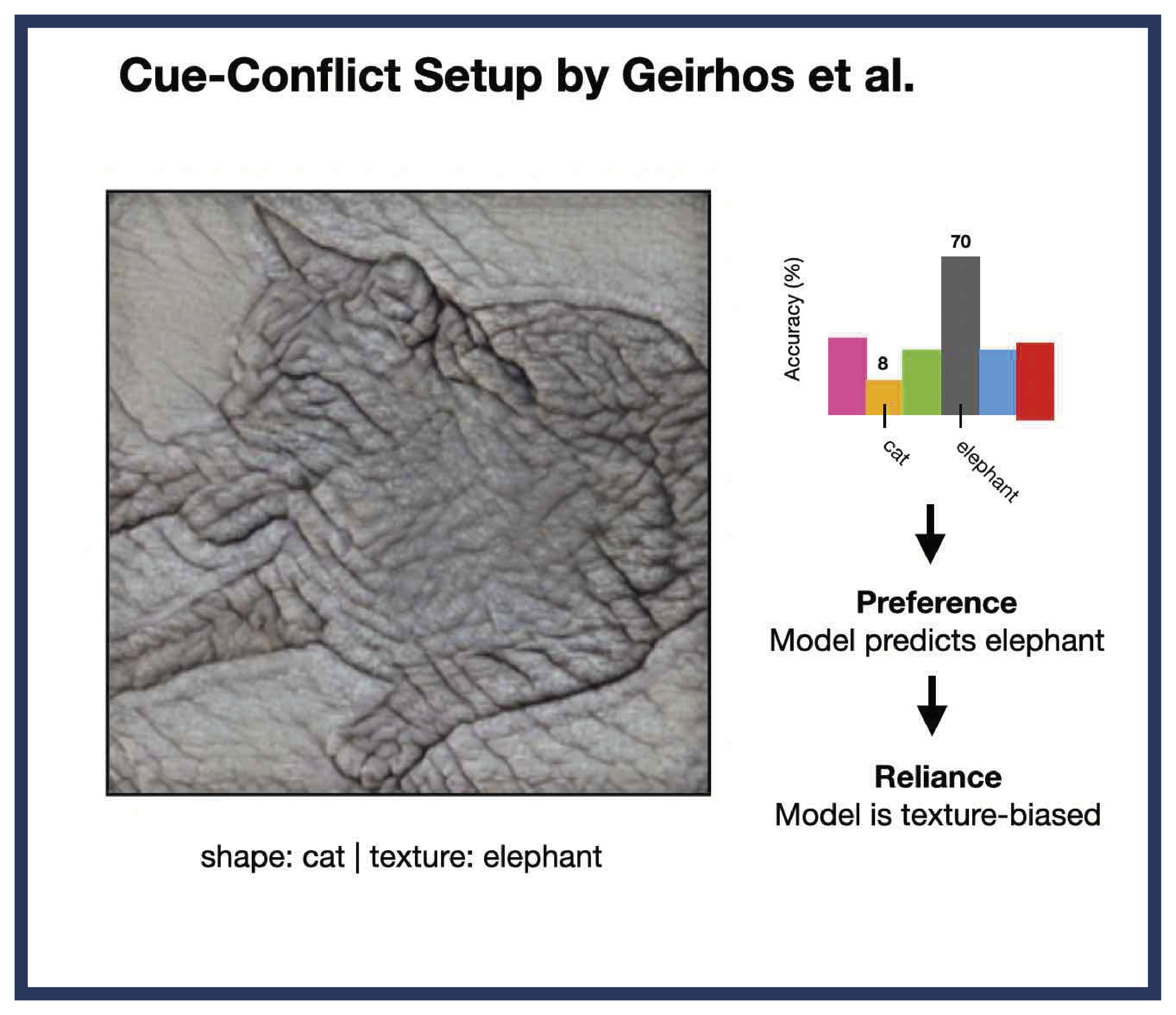
A team of BIFOLD researchers, Tom Burgert, Oliver Stoll, and Begüm Demir from TU Berlin, and Paolo Rota from the University of Trento, has developed a new study titled “ImageNet-trained CNNs are not biased towards texture: Revisiting feature reliance through controlled suppression”. The publication was accepted as an oral presentation at NeurIPS 2025 (within the top 0.35% of submissions). The work revisits a central claim in computer vision: that so-called convolutional neural networks (CNNs) primarily rely on texture, rather than object shape, to recognize images. A CNN is a deep learning architecture that infers hierarchical representations from data. It processes images in a way that allows the model to detect recurring visual patterns and distinguish different types of content with different levels of abstraction.
For years, the so-called “texture bias“ hypothesis shaped the understanding of visual AI. The idea, based on a 2019 “cue-conflict” experiment, suggested that CNNs classify images mainly by their surface texture, for example, identifying a cat because of its fur pattern. In contrast, the results suggested that humans classify primarily by shape, for example, identifying a cat because of its silhouette. The BIFOLD and Trento team showed that the experimental setup behind this study contained conceptual and methodological weaknesses.
Instead of using artificial hybrid images (for instance, a cat with elephant skin), the researchers developed a new domain-agnostic framework to systematically suppress specific visual features like texture, shape, or color and measure how model performance changes. This approach enables a cleaner, quantitative assessment of which cues a model actually depends on, without forcing an either-or choice between texture and shape.
Revisiting the “texture bias” phenomenon in deep learning models
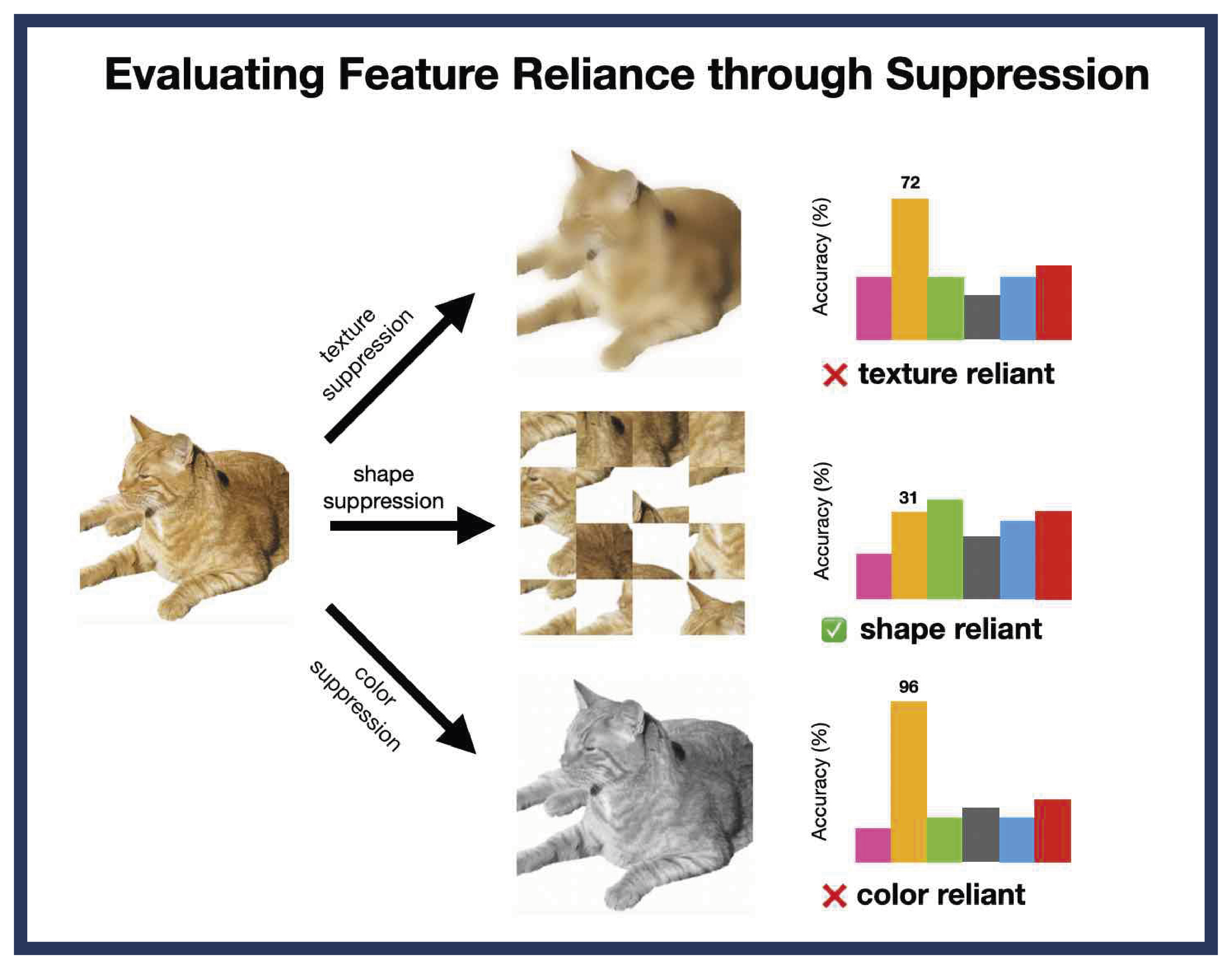
“Understanding which features models rely on, helps make them more interpretable and reliable, for example when applying AI to medical or satellite images. Using this framework, we compared human observers with a wide range of modern vision models, from classical CNNs like ResNet to transformer-based architectures such as ViT and CLIP”, explains Tom Burgert. The results suggest that feature reliance in AI vision models is not inherently texture-biased, but instead reveals a stronger reliance on local shape. Nonetheless, this local shape reliance can be mitigated by architecture and training procedures. The research originated from the aim to better compare models trained on everyday photos with those trained on satellite images, since the „cue-conflict“ experiment limited model evaluation to everyday photos. When applied across different domains, the framework revealed striking differences:
- Computer vision models (trained on everyday photos) primarily depend on shape.
- Medical imaging models emphasize color information, reflecting diagnostic cues such as tissue color.
- Remote sensing models (trained on satellite images) show a stronger reliance on texture, matching.
Together, the findings suggest that feature reliance is not a fixed model property, but it varies with architecture, training procedure, and data domain. Knowing whether a model relies on texture, shape, or color helps researchers design systems that are more interpretable, robust, and aligned with human perception. This is particularly crucial in safety-critical areas like medical diagnostics or satellite monitoring, where model errors can have real-world consequences.
“By reframing how feature reliance is measured, the study opens new paths for building AI models that can be tailored to specific applications, emphasizing the features that matter most for reliable decision-making”, summarizes Begüm Demir.
Publication:
Tom Burgert, Oliver Stoll, Paolo Rota, Begüm Demir, ImageNet-trained CNNs are not biased towards texture: Revisiting feature reliance through controlled suppression