


Gaining insight into real-world distribution shifts
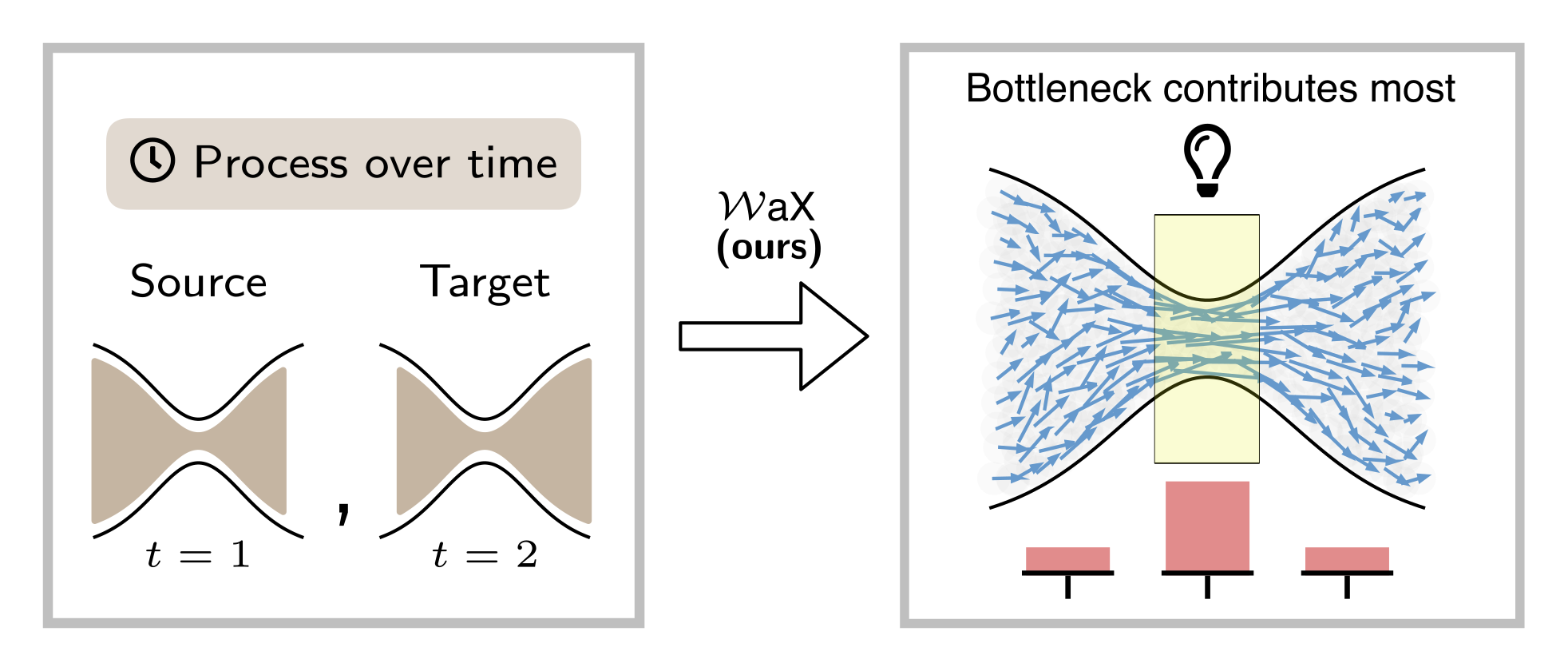
The Wasserstein distance is a mathematical measure used in machine learning and statistics to quantify differences between two data distributions. It can be used to analyze processes over time or to detect inhomogeneities within data. To compare how one dataset differs from another or how a system evolves over time, the Wasserstein distance is widely used. However, simply calculating the Wasserstein distance or analyzing the corresponding transport plan may not be sufficient for understanding what factors contribute to a high or low Wasserstein distance. While powerful in theory (e.g., in optimal transport and generative modeling), its raw value tells us only that distributions differ, not why they differ or which aspects of the data contribute most to that difference. Philip Naumann (BIFOLD), Jacob Kauffmann (BIFOLD), and Grégoire Montavon (Charité - Universitätsmedizin Berlin and BIFOLD) have developed a novel framework to make a foundational statistical tool, the Wasserstein distance, interpretable in machine learning and data analysis contexts. Their publication appeared as an early access paper in IEEE Transactions on Pattern Analysis and Machine Intelligence. The new method introduced in this paper, informally dubbed “WaX” (Wasserstein distances made explainable), bridges this interpretability gap
WaX: Negligible computation time
The research team frames the problem of explaining Wasserstein distances within the broader context of Explainable AI (XAI). Rather than treating the distance as a black-box scalar, WaX reformulates the Wasserstein computation in a way that allows the contributions of individual data points, input features, and interpretable subspaces to be quantified. Technically, this involves re-expressing the distance calculation as a kind of neural-network-like computation so that established attribution methods (such as layer-wise relevance propagation) can assign meaningful scores to components of the input data.
First author Philip Naumann: “A distinctive advantage of our method is its remarkable speed. The computation time of WaX is negligible compared to the calculation of the Wasserstein distance. Thus, our method can be efficiently applied to real-world transport problems.”
To demonstrate their approach, the authors apply WaX in three different use cases. For example, they show on a simulated aging cohort how the method can deliver insights into main development trends. In another use case, they show how WaX can be used to identify systematic issues in dataset coverage, such as imbalances in the representation of population subgroups. Overall, these use cases demonstrate how WaX can uncover structured patterns of change that would otherwise remain hidden in a plain comparison of distributions.
Grégoire Montavon: “By providing a method to explain Wasserstein distances, a widely used tool, WaX offers researchers and practitioners a way to interpret distributional shifts rather than merely measure them. This has broad implications across fields where distribution comparison is central, from robustness analysis in machine learning to domain adaptation, dataset curation, and even scientific studies of temporal dynamics in biological or physical systems.”
Publication
Philip Naumann, Jacob Kauffmann, Grégoire Montavon: “Wasserstein Distances Made Explainable: Insights Into Dataset Shifts and Transport Phenomena, IEEE Transactions on Pattern Analysis and Machine Intelligence.