



The project Sphere: Knowledge System Evolution and the Shared Scientific Identity of Europe is one of the leading Digital Humanities projects, exploring a large corpus of more than 350 book editions about geocentric cosmology and astronomy from the early days of printing between the 15th and the 17th centuries (Sphaera Corpus) for about 76.000 pages of material. The relatively large size of this humanities dataset presents a challenge to traditional historical approaches, but provides a great opportunity to computationally explore such a large collection of books. In this regard, the Sphere project is an incubator of multiple Digital Humanities (DH) approaches aimed at answering various questions about the corpus, with the ultimate objective to understand the evolution and transmission of knowledge in the early modern period.
At the base of all the computation approaches within the Sphere project lies its large knowledge graph modelled according to the CIDOC-CRM ontology . This ever-expanding knowledge graph contains detailed metadata on all the editions in the Sphaera corpus, as well as all the people involved in their composition and production. “Relying on this database, we were able to construct a multiplex network whose nodes represent the editions in our corpus, and whose edges represent various semantic relations” say Prof. Dr. Matteo Valleriani, research group leader at the Max Planck Institute for the History of Science, PI at BIFOLD, Honorary Professor at TU Berlin and Professor for Special Appointment at the University of Tel Aviv. The detailed analysis of this multiplex network shed the light on numerous influential and important editions within the Sphaera corpus.
Some of these editions show disruptive behavior that executed long term significant impact on the corpus, which are called enduring innovations. As an example a Spanish edition published in 1535 by Francesco Faleiro has been identified that, besides basic cosmological doctrine of the time, also contains a compact report about pressing issues of the time, such as the art of navigation and particularly the subject of the magnetic variations that made compass use on ships challenging on transoceanic travels during the sixteenth century. Other editions played instead a major role in collecting information from past editions and passed them on towards future ones; They are called great transmitters.
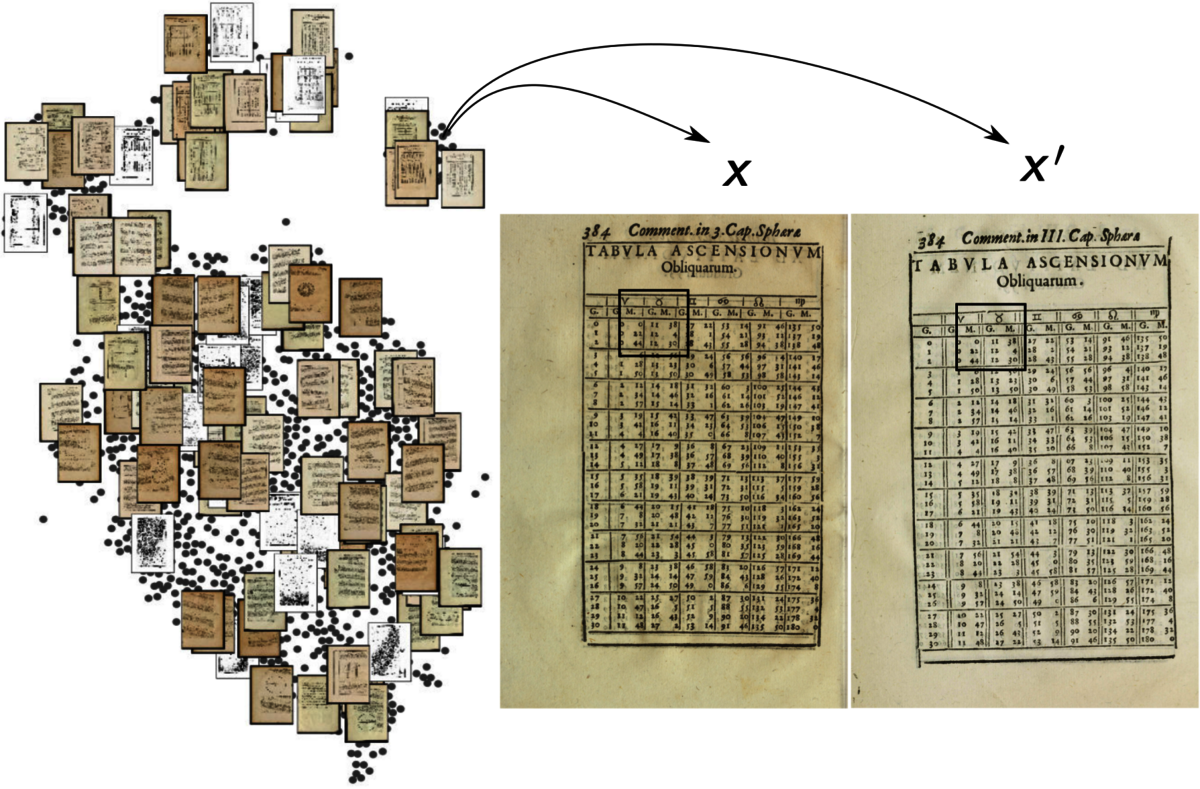
By looking at the content of the Sphaera editions, the scientists investigated two different elements that often repeat across the corpus, astronomical tables and visual elements, and used those as proxy to better understand the evolution of knowledge. We first extracted all the pages containing a table from every edition of our corpus using a neural network, which totaled ca. 10.000 pages. While this might sound trivial, the most difficult task is identifying similar tables. Although the content of some tables might have remained the same, their designs potentially changed considerably. To solve this problem, we used the histogram output of a bigram network to calculate the similarity score between the 10.000 tables with pages (Fig. 1).
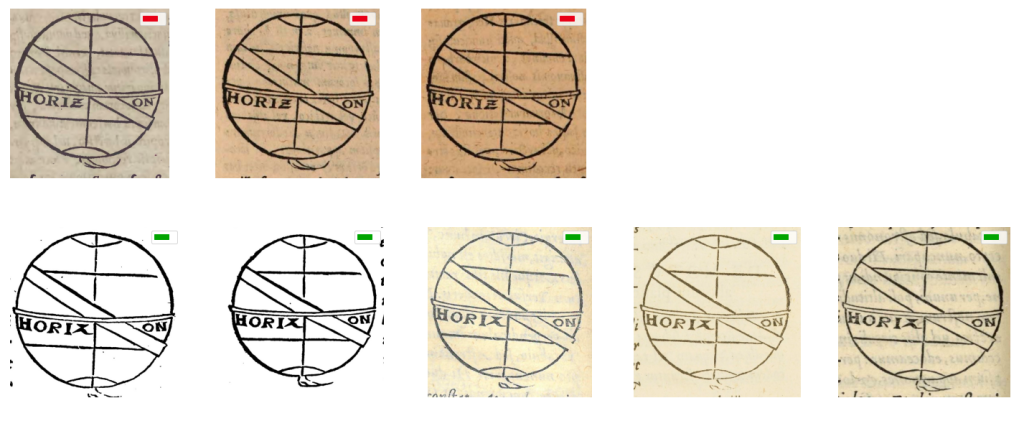
This was further validated using BiLRP, an Explainable AI method, to ensure that the results are justifiable. “When it comes to visual elements, we developed a workflow to extract, compare, and analyze the over 30.000 visual elements. This involved a neural network architecture to extract them from the corpus’ pages, which is followed by a rigorous similarity analysis, combing neural networks and standard computer vision approaches, the results of which are confirmed by domain experts. Using this workflow, we were able to identify numerous visual elements that were printed using the same woodblocks” explains Matteo Valleriani. (Fig. 2).
All this generated information eventually makes its way back into the Sphaera knowledge graph. With the increased amount of information representing each Sphaera edition (e.g. tables, images, text-parts, etc.), the data scientist Hassan el-Hajj developed the cidoc2vec approach to leverage knowledge graph structure and generate a vector representation of these editions. In this way, similarities between editions based on their stored metadata were highlighted, and several re-print clusters, where the producer reprinted the same content with minimal changes over a long period of time could also be easily identified.
All these studies help to better understand the dynamics of the homogenization of knowledge, which can be described as a mechanism of imitation, centered on the reformed Wittenberg. It ensured that at the end of the 16th century, students of astronomy across Europe were learning the same concepts. “As a digital humanities incubator, the Sphere project plays a major role in re-defining how we think about studying history, how we deal with big humanities data, and how we can convert computationally obtained results into sound historical hypotheses” summarizes Matteo Valleriani.
The publication in detail:
Hassan El-Hajj, Maryam Zamani, Jochen Büttner, Julius Martinetz, Oliver Eberle, Noga Shlomi, Anna Siebold, Grégoire Montavon, Klaus-Robert Müller, Holger Kantz & Matteo Valleriani: An Ever-Expanding Humanities Knowledge Graph: The Sphaera Corpus at the Intersection of Humanities, Data Management, and Machine Learning, Datenbank Spektrum (2022).
Update April 11 2023: The MIT Technology Review reports about the Sphere and CORDEEP project
Article: How AI is helping historians better understand our past - The historians of tomorrow are using computer science to analyze how people lived centuries ago. / Author: Moira Donovan / Published: April 11, 2023 / Link: https://www.technologyreview.com/2023/04/11/1071104/ai-helping-historians-analyze-past/