


Neural networks have found their way into many every day applications. During the past years they reached excellent performances on various largescale prediction tasks, ranging from computer vision, language processing or medical diagnosis. Even if in recent years AI research developed various techniques that uncover the decision-making process and detect so called “Clever Hans” predictors – there exists no ground truth-based evaluation framework for such explanation methods. BIFOLD researcher Dr. Wojciech Samek and his colleagues now established an Open Source ground truth framework, that provides a selective, controlled and realistic testbed for the evaluation of neural network explanations. The work will be published in Information Fusion.
Imagine a doctor giving a life changing diagnosis based on the prediction of a neural network or an employer denying an application relying on the prediction of a neural network. From an end-user perspective it is not only desirable but necessary and often even legally required to accompany a model’s decision with an explanation in order to trace it back to the decisive parts of the input. These models must be based on genuinely solving a given problem, and not on exploiting spurious correlations found in the data. Explainable AI (XAI) research has recently developed various techniques to uncover the decision making process of the model. Beyond that, XAI bears also the potential to help improve model performance and efficiency, or to enable new data-driven scientific discoveries.
In the vision domain, the explanation of AI models can take the form of a heatmap, where each pixel in an input image gets assigned a relevance value or score, indicating its relative contribution to the final decision. So far XAI methods along with their heatmaps were mainly validated qualitatively via human-based assessment, or evaluated through auxiliary proxy tasks such as pixel perturbation, weak object localization or randomization tests. Due to the lack of an objective and commonly accepted quality measure for heatmaps, it was debatable which XAI method performs best and whether explanations can be trusted at all.
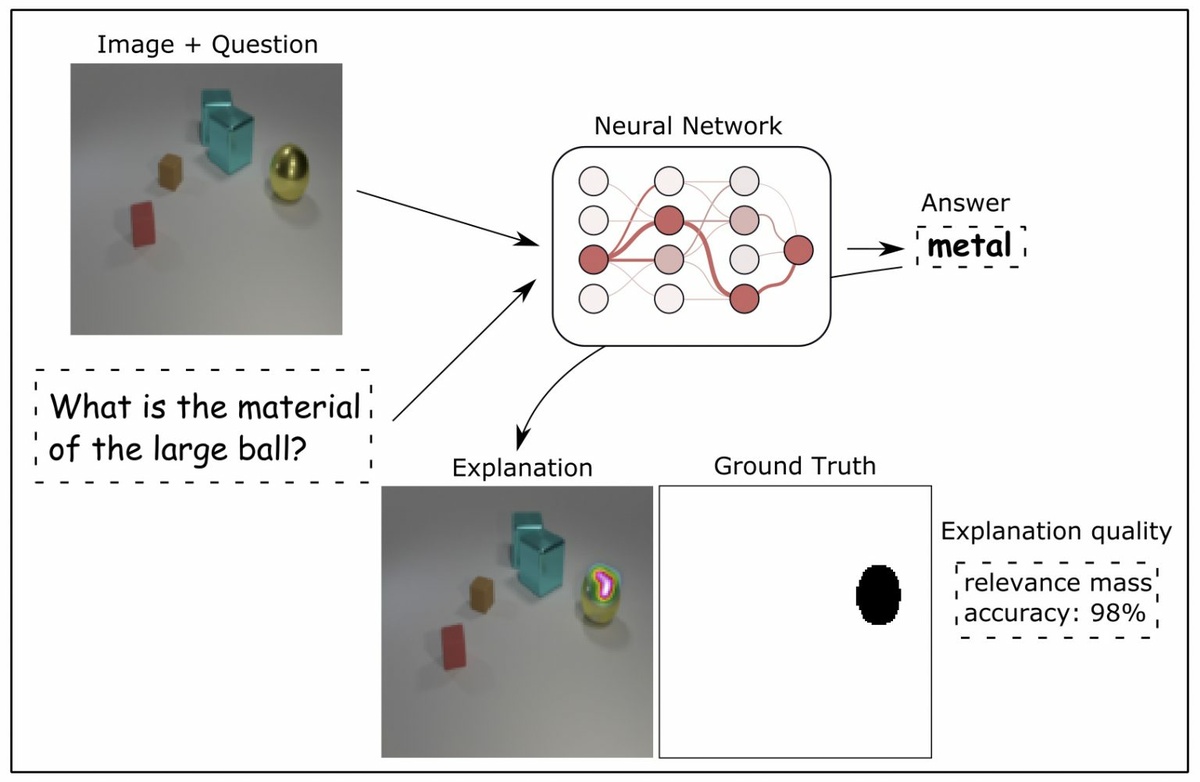
Wojciech Samek and his colleagues propose instead to evaluate explanations directly against ground truth object coordinates using a restricted setup of synthetic, albeit realistically rendered, images of 3D geometric shapes. “To the best of our knowledge, this is the first ground truth based and realistic testbed for the evaluation of neural network explanations proposed in the literature,” says Wojciech Samek. The evaluation is based on “Visual Question Answering”. “We train a complex neural network that is able to answer questions about images. We give the model a generated image with different objects (3D shapes). Since we have full control over the generation of the image – which object is where – as well as the generation of the question, we know exactly what the model has to look at to answer the question. We know what is relevant. For example: The gray background contains no information at all and should not be marked as relevant by a reliable, explanatory method. With this method we can not only measure exactly how good an XAI method is. We can also compare them for the first time really objectively while performing a difficult task.” The CLEVR-XAI dataset, that the researchers provide open source, consists of 10.000 images and 140.000 questions, divided into simple and complex questions. Simple questions pertain to one object in the image, while complex questions can pertain to multiple. “Another key contribution of our paper is the systematic comparison of the eleven most widely used XAI techniques,” explains Wojciech Samek. “We were extremely happy to find that the LRP (Layer-wise Relevance Propagation) method, that was established in a BIFOLD project between Klaus-Robert Müller and myself, was asserted and could establish itself among the best performing methods.”
The CLEVR-XAI dataset and the benchmarking code can be found on Github.
The publication in detail:
Leila Arras, Ahmed Osman, Wojciech Samek: CLEVR-XAI: A benchmark dataset for the ground truth evaluation of neural network explanations. Inf. Fusion 81: 14-40 (2022)
The rise of deep learning in today’s applications entailed an increasing need in explaining the model’s decisions beyond prediction performances in order to foster trust and accountability. Recently, the field of explainable AI (XAI) has developed methods that provide such explanations for already trained neural networks. In computer vision tasks such explanations, termed heatmaps, visualize the contributions of individual pixels to the prediction. So far XAI methods along with their heatmaps were mainly validated qualitatively via human-based assessment, or evaluated through auxiliary proxy tasks such as pixel perturbation, weak object localization or randomization tests. Due to the lack of an objective and commonly accepted quality measure for heatmaps, it was debatable which XAI method performs best and whether explanations can be trusted at all. In the present work, we tackle the problem by proposing a ground truth based evaluation framework for XAI methods based on the CLEVR visual question answering task. Our framework provides a (1) selective, (2) controlled and (3) realistic testbed for the evaluation of neural network explanations. We compare ten different explanation methods, resulting in new insights about the quality and properties of XAI methods, sometimes contradicting with conclusions from previous comparative studies.
The rise of deep learning in today’s applications entailed an increasing need in explaining the model’s decisions beyond prediction performances in order to foster trust and accountability. Recently, the field of explainable AI (XAI) has developed methods that provide such explanations for already trained neural networks. In computer vision tasks such explanations, termed heatmaps, visualize the contributions of individual pixels to the prediction. So far XAI methods along with their heatmaps were mainly validated qualitatively via human-based assessment, or evaluated through auxiliary proxy tasks such as pixel perturbation, weak object localization or randomization tests. Due to the lack of an objective and commonly accepted quality measure for heatmaps, it was debatable which XAI method performs best and whether explanations can be trusted at all. In the present work, we tackle the problem by proposing a ground truth based evaluation framework for XAI methods based on the CLEVR visual question answering task. Our framework provides a (1) selective, (2) controlled and (3) realistic testbed for the evaluation of neural network explanations. We compare ten different explanation methods, resulting in new insights about the quality and properties of XAI methods, sometimes contradicting with conclusions from previous comparative studies.