






Researchers at TU Berlin Database Systems and Information Management (DIMA) group and Intelligent Analytics for Massive Data (IAM) group at DFKI presented one full paper, one demo paper and three PhD thesis papers at the 46th International Conference on Very Large Databases (VLDB 2020).
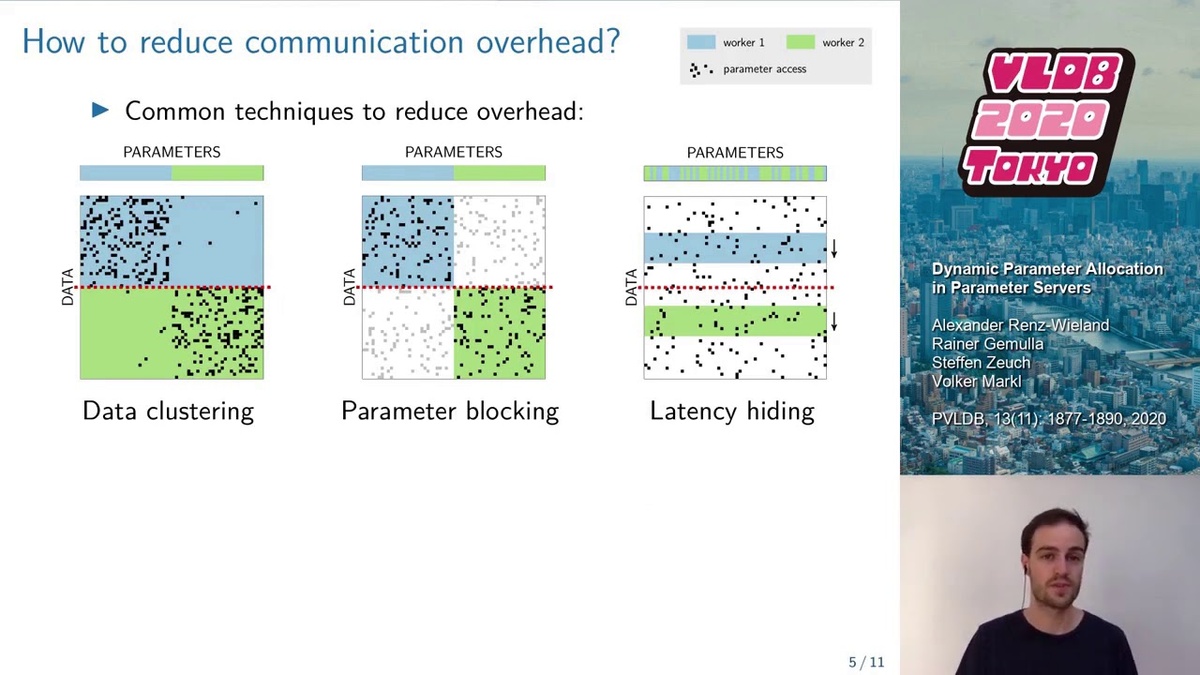
The Paper “Dynamic Parameter Allocation in Parameter Servers” by Alexander Renz-Wieland et al. proposes to integrate dynamic parameter allocation into parameter servers, describes an efficient implementation of such a parameter server called Lapse, and experimentally compares its performance to existing parameter servers across a number of machine learning tasks.
To watch the recording of Alexander Renz-Wieland’s talk please visit: https://www.youtube.com/watch?v=aMSjPW8Dmc0
The paper is available here: https://www.vldb.org/pvldb/vol13/p1877-renz-wieland.pdf
In the demo paper “Demand-based Sensor Data Gathering with Multi-Query Optimization” Julius Hülsmann et al. demonstrate a technique for minimizing the number of network transmissions while maintaining the desired accuracy. The presented algorithm for read- and transmission sharing among queries goes hand-in-hand with state-of-the-art machine learning techniques for adaptive sampling. We 1. implement the technique and deploy it on a sensor node, 2. replay sensor-data from two real-world scenarios, 3. Provide an interface for submitting custom queries, and 4. Present an interactive dashboard. Here, visitors observe live statistics on the read- and transmission savings achieved in real-world use-cases. The dashboard also visualizes optimizations currently performed by the read scheduling procedure and hence conveys real-time insights and a deep understanding of the presented algorithm.
To watch the recording of Julius Hülsmann’s talk please visit: https://www.youtube.com/watch?v=ctpj-o3b4B4
The paper is available here: http://www.vldb.org/pvldb/vol13/p2801-hulsmann.pdf
At this year’s International Workshop on Very Large Internet of Things (VLIOT 2020), held in conjunction with VLDB 2020, Dr. Steffen Zeuch et al. presented their IoT analytics paper “NebulaStream: Complex analytics beyond the Cloud” . The goal of this paper is to bridge the gap between the requirements of upcoming IoT applications and the supported features of an IoT data management system. To this end, we outline how state-of-the-art SPEs have to change to exploit the new capabilities of the IoT and showcase how we tackle IoT challenges in our own system, NebulaStream. This paper lays the foundation for a new type of systems that leverages the IoT to enable large-scale applications over millions of IoT devices in highly dynamic and geodistributed environments.
To watch the recording of Steffen Zeuch’s talk please visit: https://www.youtube.com/watch?v=PCvihOXjhI8
The paper is available here: https://www.ronpub.com/ojiot/OJIOT_2020v6i1n07_Zeuch.html
Also in conjunction with VLDB 2020, the 2nd International Workshop on Large Scale Graph Data Analytics (LSGDA 2020) took place this year on September 04. Based on his paper “Distributed Graph Analytics with Datalog Queries in Flink“, co-authored by Gábor Gévay and Prof. Dr. Volker Markl, Muhammad Imran presented the Cog system that runs Datalog programs on Apache Flink. The authors implemented a parallel semi-naive evaluation algorithm that takes advantage of Flink’s delta iteration to propagate only the tuples that need to be processed for subsequent iterations. Flink’s delta iteration function reduces the overhead that occurs in acyclic data flow systems like Spark when evaluating recursive queries, making them more efficient. Their experiments show that Cog outperformed BigDatalog, the state-of-the-art distributed data-log evaluation system, in most tests.
To watch a recording of Muhammad Imran’s talk please visit: https://www.youtube.com/watch?v=Ozvr1wrQcy4
A preprint of the paper is available here: https://bit.ly/2HhzIsh
Additionally, three PhD students presented their work during the VLDB 2020 PhD workshop:
Serafeim Papadias : “Tunable Streaming Graph Embeddings at Scale”
Presentation | Paper
Kajetan Maliszewski : “Secure Data Processing at Scale”
Presentation | Paper
Ariane Ziehn : “Complex Event Processing for the Internet of Thing”
Paper
To learn more about VLDB 2020 please visit: https://vldb2020.org/