


The research paper “Fast CSV Loading Using GPUs and RDMA for In-Memory Data Processing” by Alexander Kumaigorodski, Clemens Lutz, and Volker Markl received the Best Paper Award of the 19th Symposium on Database Systems for Business, Technology and Web (BTW 2021). On top, the paper received the Reproducibility Badge, awarded for the first time by BTW 2021, for the high reproducibility of its results.
TU Berlin Master’s graduate Alexander Kumaigorodski and his co-authors from Prof. Dr. Volker Markl‘s Department of Database Systems and Information Management (DIMA) at TU Berlin and from the Intelligent Analytics for Massive Data (IAM) research area at the German Research Centre for Artificial Intelligence (DFKI) present a new approach to speed up loading and processing of tabular CSV data by orders of magnitude.
CSV is a very frequently used format for the exchange of structured data. For example, the City of Berlin publishes its structured datasets in the CSV format in the Berlin Open Data Portal. Such datasets can be imported into databases for data analysis. Accelerating this process allows users to handle the increasing amount of data and to decrease the time required for its data analysis. Each new generation of computer networks and storage media provides higher bandwidths and allows for faster reading times. However, current loading and processing approaches using main processors (CPU) cannot keep up with these hardware technologies and unnecessarily throttle loading times.
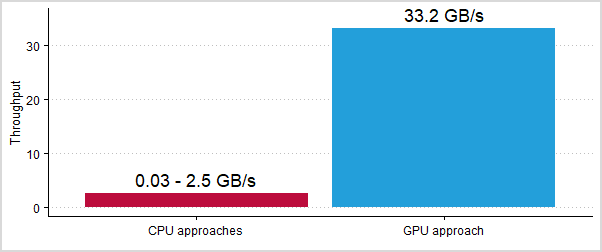
The procedure described in this paper uses a new approach where CSV data is read and processed by graphics processors (GPU) instead. The advantage of these graphics processors lies primarily in their strong parallel computing power and fast memory access. Using this approach, new hardware technologies can be fully made use of, e.g., NVLink 2.0 or InfiniBand with Remote Direct Memory Access (RDMA). In conclusion, CSV data can be read directly from main memory or the network and processed with multiple gigabytes per second.
The transparency of the tests performed and the independent confirmation of the results also led to the award of the first-ever BTW 2021 Reproducibility Badge. In the data science community, the reproducibility of research results is becoming increasingly important. It serves to verify results as well as to compare them with existing work and is thus an important aspect of scientific quality assurance. Leading international conferences have therefore already devoted special attention to this topic.
To ensure high reproducibility, the authors provided the reproducibility committee with source code, additional test data, and instructions for running the benchmarks. The execution of the tests was demonstrated in a live session and could then also be successfully replicated by a member of the committee. The Reproducibility Badge recognizes above all the good scientific practice of the authors.
THE PAPER IN DETAIL:
Authors:
Alexander Kumaigorodski, Clemens Lutz, Volker Markl
Abstract:
Comma-separated values (CSV) is a widely-used format for data exchange. Due to the format’s prevalence, virtually all industrial-strength database systems and stream processing frameworks support importing CSV input. However, loading CSV input close to the speed of I/O hardware is challenging. Modern I/O devices such as InfiniBand NICs and NVMe SSDs are capable of sustaining high transfer rates of 100 Gbit/s and higher. At the same time, CSV parsing performance is limited by the complex control flows that its semi-structured and text-based layout incurs. In this paper, we propose to speed-up loading CSV input using GPUs. We devise a new parsing approach that streamlines the control flow while correctly handling context-sensitive CSV features such as quotes. By offloading I/O and parsing to the GPU, our approach enables databases to load CSVs at high throughput from main memory with NVLink 2.0, as well as directly from the network with RDMA. In our evaluation, we show that GPUs parse real-world datasets at up to 60 GB/s, thereby saturating high-bandwidth I/O devices.
Publication:
K.-U. Sattler et al. (Hrsg.): Datenbanksysteme für Business, Technologie und Web (BTW 2021),Lecture Notes in Informatics (LNI), Gesellschaft für Informatik, Bonn 2021
https://doi.org/10.18420/btw2021-01
Authors:
Alexander Kumaigorodski, Clemens Lutz, Volker Markl
Abstract:
Comma-separated values (CSV) is a widely-used format for data exchange. Due to the format’s prevalence, virtually all industrial-strength database systems and stream processing frameworks support importing CSV input. However, loading CSV input close to the speed of I/O hardware is challenging. Modern I/O devices such as InfiniBand NICs and NVMe SSDs are capable of sustaining high transfer rates of 100 Gbit/s and higher. At the same time, CSV parsing performance is limited by the complex control flows that its semi-structured and text-based layout incurs. In this paper, we propose to speed-up loading CSV input using GPUs. We devise a new parsing approach that streamlines the control flow while correctly handling context-sensitive CSV features such as quotes. By offloading I/O and parsing to the GPU, our approach enables databases to load CSVs at high throughput from main memory with NVLink 2.0, as well as directly from the network with RDMA. In our evaluation, we show that GPUs parse real-world datasets at up to 60 GB/s, thereby saturating high-bandwidth I/O devices.
Publication:
K.-U. Sattler et al. (Hrsg.): Datenbanksysteme für Business, Technologie und Web (BTW 2021),Lecture Notes in Informatics (LNI), Gesellschaft für Informatik, Bonn 2021
https://doi.org/10.18420/btw2021-01